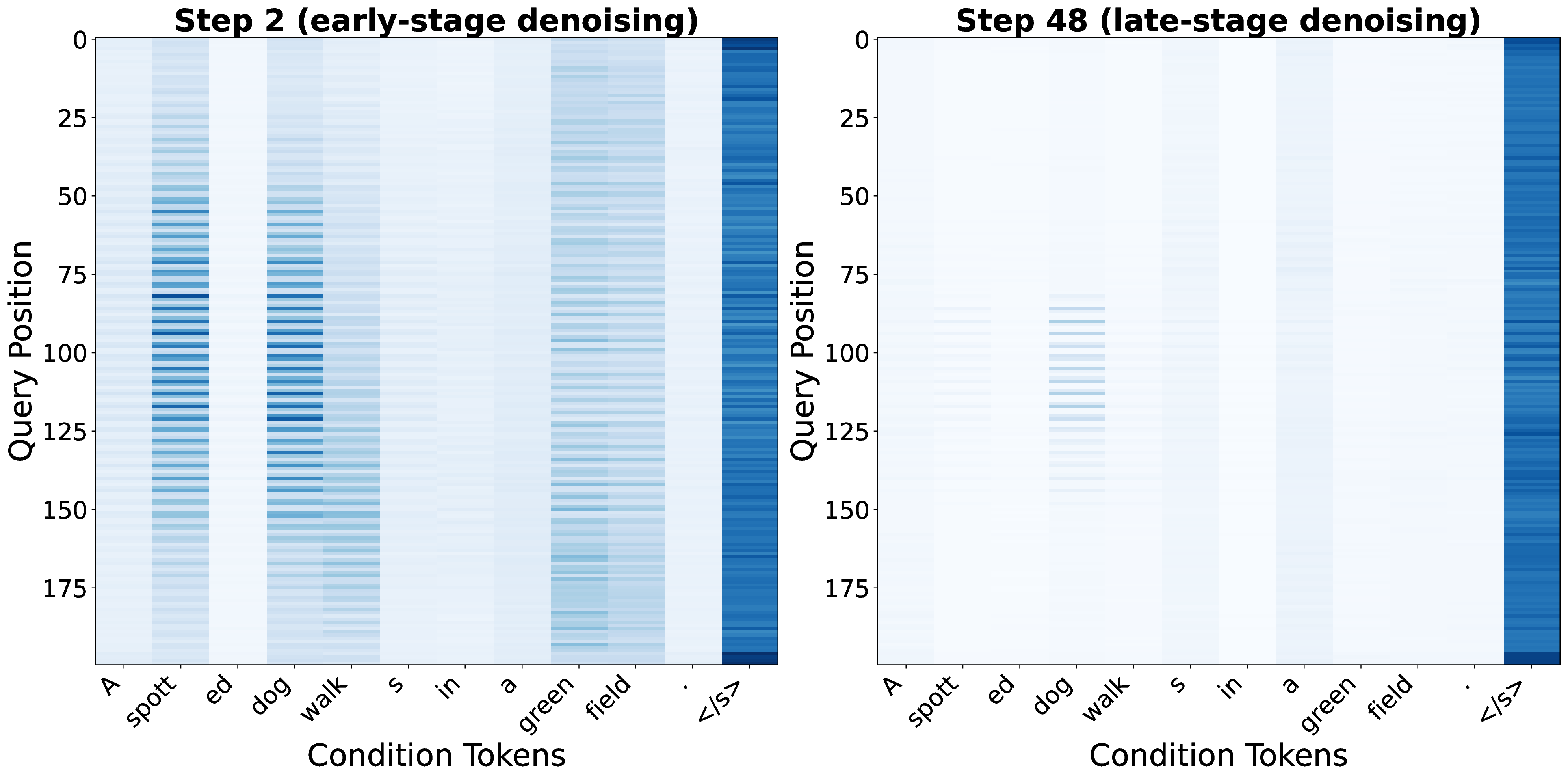
Introduction
Video DiT models like Wan and HunyuanVideo produce high-quality videos but are prohibitively expensive. Chorus introduces inter-request caching reuse to break this bottleneck.

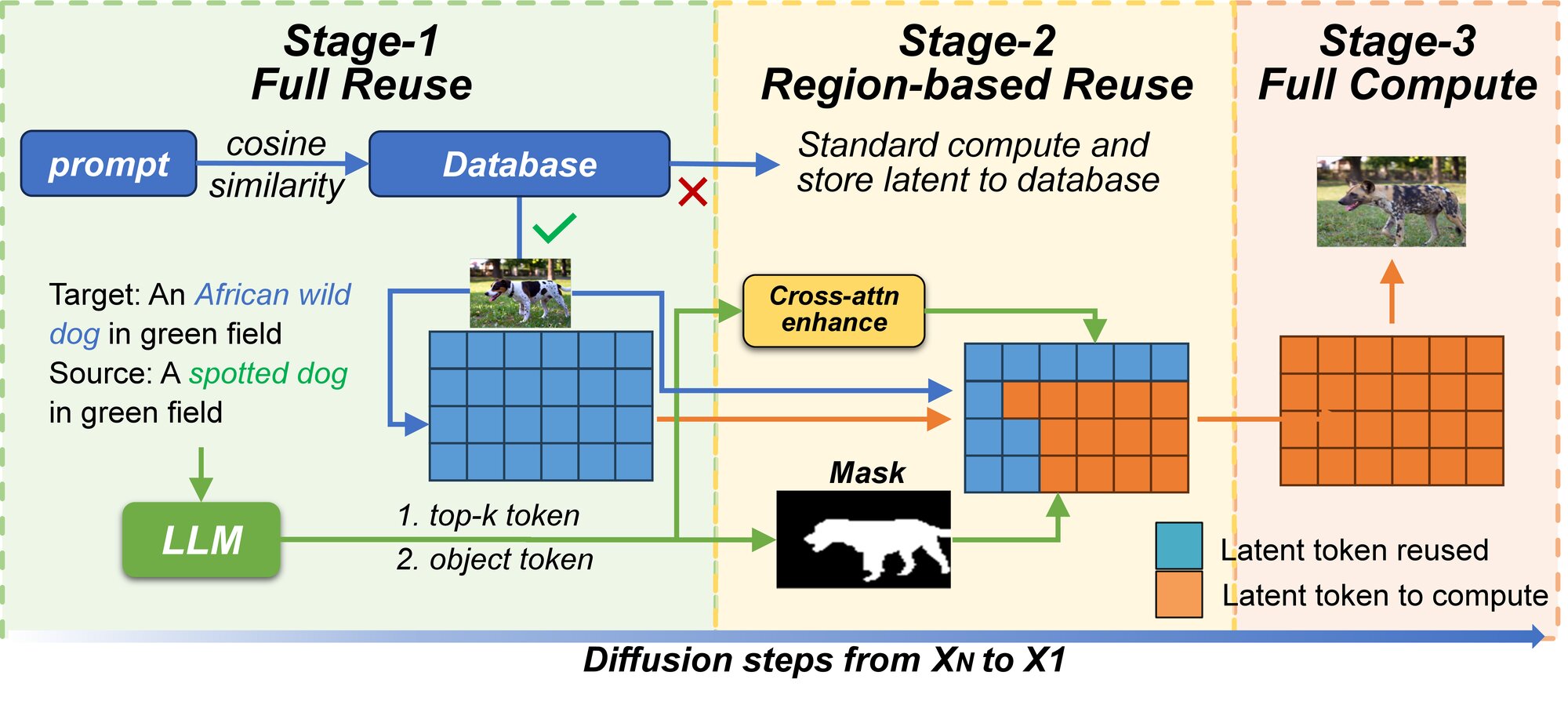
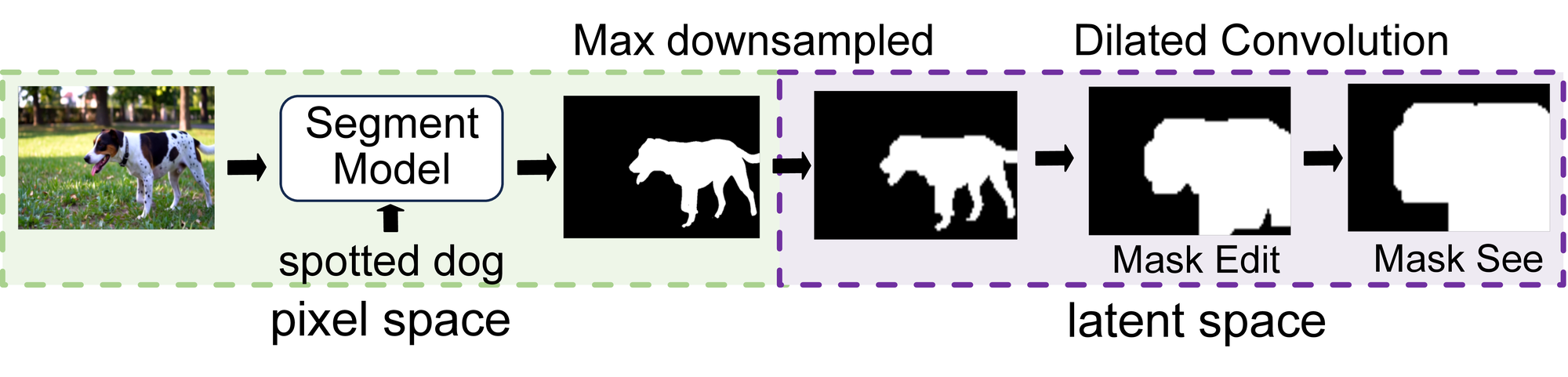
Figure 1. Video generation illustration of Chorus on a distilled 4-step Wan2.1 model. Chorus reuses cached latent states from a semantically similar request, significantly accelerating inference while maintaining accurate semantic generation.
💡 Key Insight
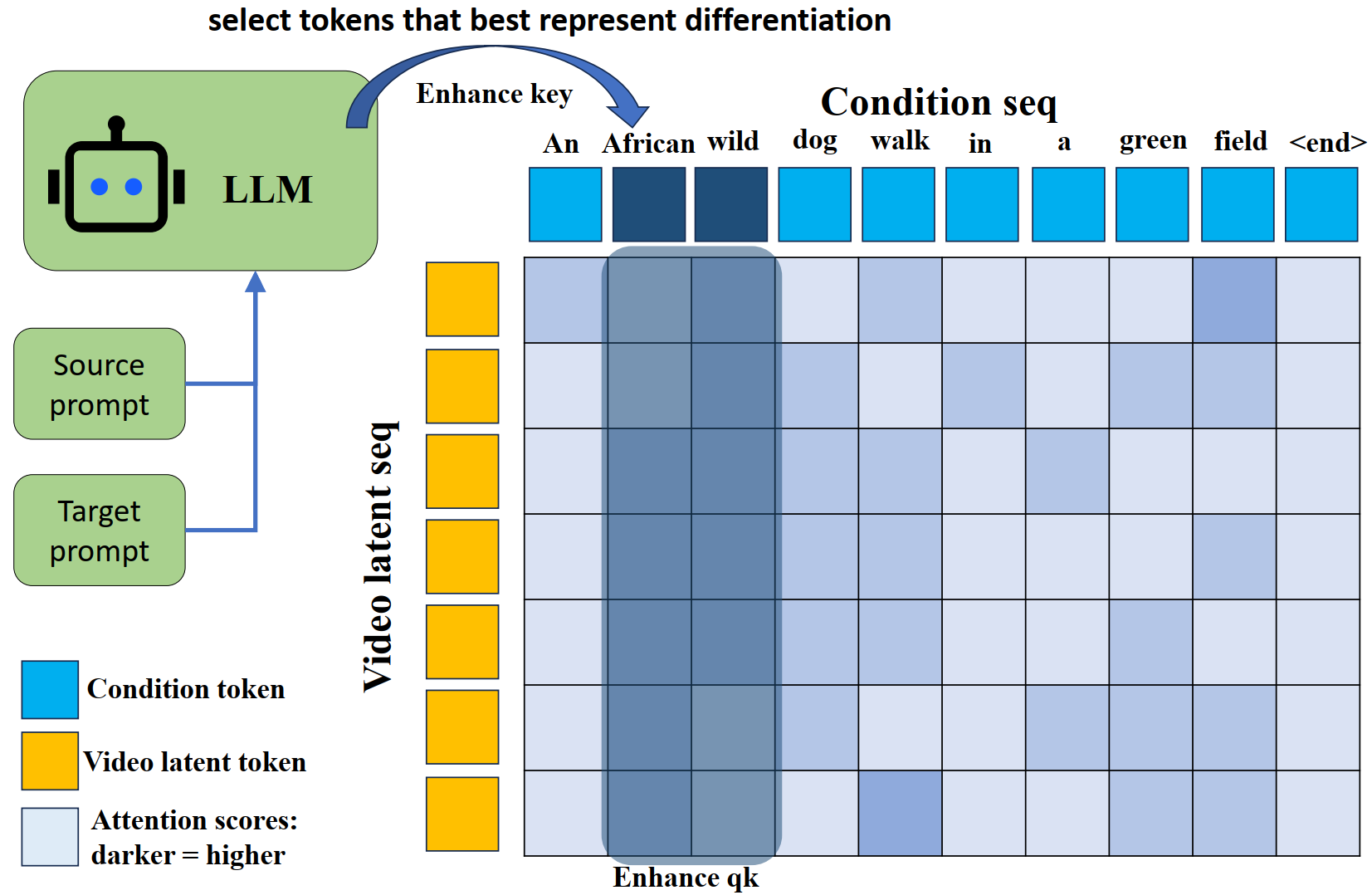
While intra-request caching exploits similarity within a single denoising process, Chorus exploits similarity across different requests. This makes it effective even on 4-step distilled models where intra-request redundancy has been largely removed. Moreover, Chorus is orthogonal to distillation and intra-request caching — combining them yields multiplicative speedups.
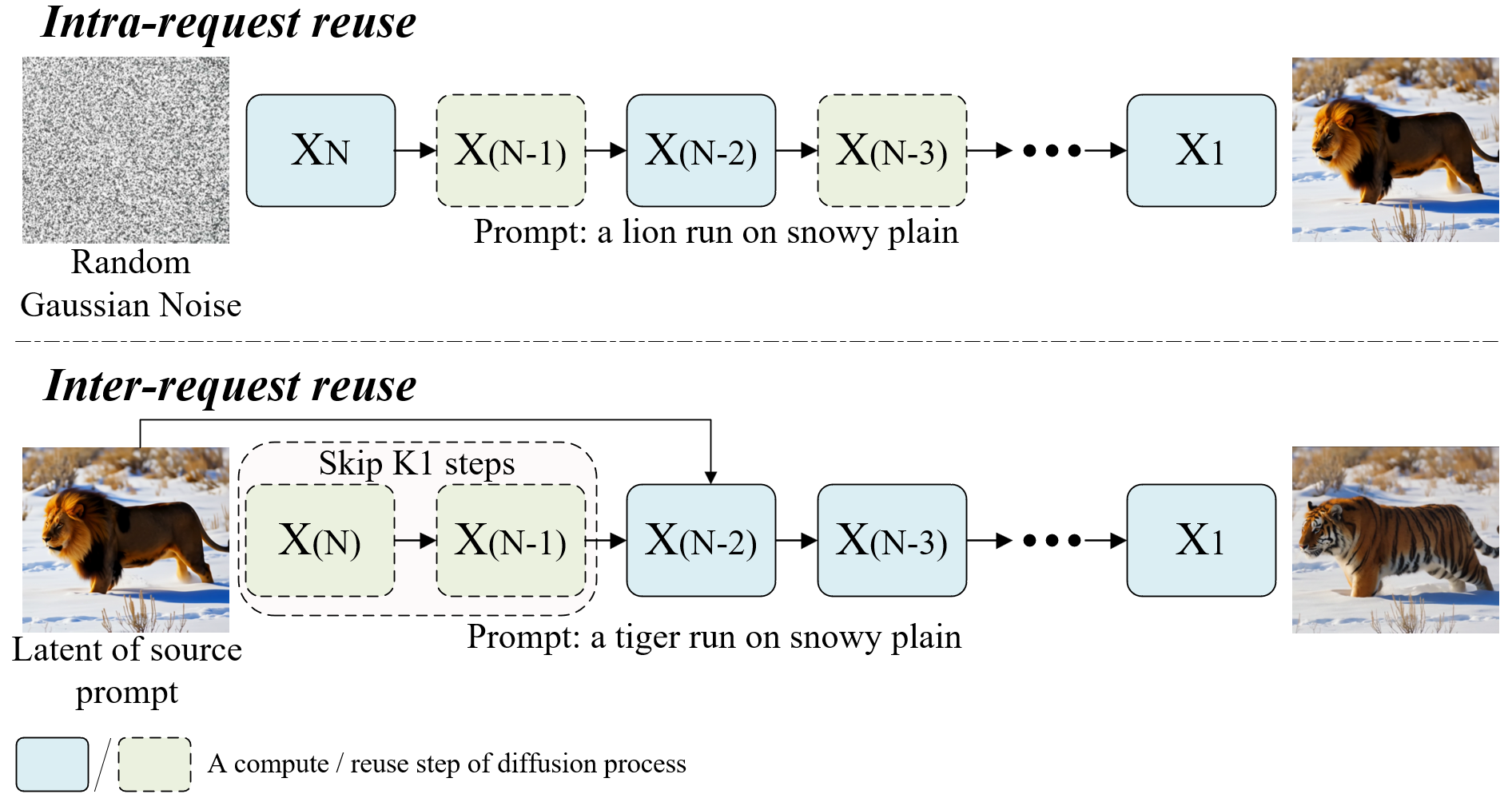
Figure 2. Illustration of intra- and inter-request caching reuse, with denoising timesteps explicitly expanded. Inter-request reuse leverages similarity across different user requests.